
I previously posted about Valve’s stance on AI-generated art on Steam and how their policy – or lack thereof at the time – really doesn’t change anything. It was just Valve not allowing copyright infringement on their platform, and taking a bit of a cautious approach until the law is settled.

Since then, Valve issued some actual policy and clarification as well as measures that they will be taking to allow AI-generated art on their platform with some consistency as well as maintain some guardrails for themselves with regards to infringing content. Things are still a bit vague with regard to some of the specifics, so we’re going to take a closer look at what this means.
Steam is Requiring Developers to Disclose How They’re Using AI in Their Games
The first update from Valve is that they’re requiring developers on Steam to disclose how they’re using AI-generated art in their game’s development process. This will be a part of the Content Survey that all developers need to fill out when submitting their games to Steam.
AI in game development is divided into two broad categories. The first is pre-generated assets, or any art, code, sound, or other assets that were “created with the help of AI tools during development.” This is where a developer would use AI-generated images or other content to create assets that are used in their game like any other asset that would be created by a human. Pre-generated assets are the most common.
The second category is live-generated. This is content “created with the help of AI tools while the game is running.” Unlike the first category, live-generated content is created while the game is running using an AI model either on the user’s machine or remotely, so it will be unique with each playthrough. Think of this as integrating ChatGPT or other similar products into your game directly. One such example is The Portopia Serial Murder Case created by Square Enix which uses a Natural Language Processor to understand and output text, to mixed results.
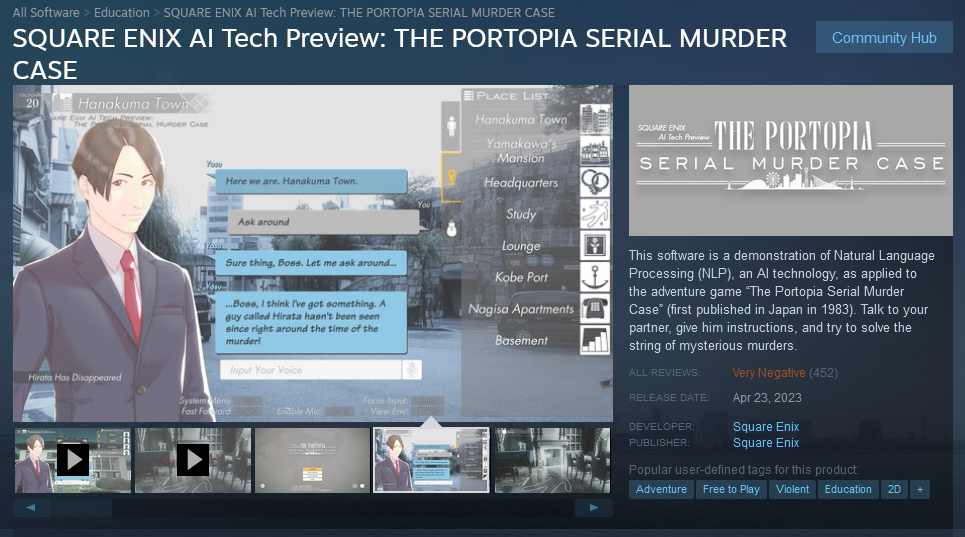
When using this type of AI in a game, developers have to answer additional questions about what sorts of guardrails they’re putting on their AI to ensure it’s not generating illegal or otherwise legally problematic outputs. There will be an option added to the Steam in-game overlay that will allow players to submit a report when they encounter content that should have been caught by these guardrails.
The use of either of these types of AI-generated content will require developers to disclose its use, and much of the disclosure will be a part of the Steam store page, which will allow customers to understand how a game uses AI. Although we don’t currently know what this will look like on the store page, it will likely be similar to other customer disclosures on Steam, which are put at the top of the store description.
Do I have to disclose if I’m using assets generated by AI models if I’m only using them as part of the store page, like as part of a capsule image, and not as part of the actual game?
While Valve’s policy doesn’t give a black and white answer to this, keep in mind that this is part of the review of your store page rather than the game itself, and that the Steam AI disclosure survey asks about “how you are using AI in the development and execution of your game” (emphasis added) which would likely include the store page. The store page and its assets are part of the commercial product you are making and promising to customers.
When in doubt, disclose it. You don’t want to end up running afoul of Steam’s policies and finding out later.
Valve’s AI Policy Change Still Centers Around Avoiding Copyright Infringement
Both of these categories require that developers make some affirmations to Valve. Developers affirm that their games “will not include illegal or infringing content, and that [the] game will be consistent with [their] marketing materials.”
So what does this actually mean? The main question is not whether you can have a copyright in AI-generated assets included in your game; right now case law suggests that you can’t.1 The real question is whether or not including work protected by copyright in an AI dataset constitutes infringement. If so, then the output images included in a game on Steam would also be infringement, and it would violate this policy against “illegal or infringing content.”

Right now, the law isn’t completely settled on this question. Some argue that it’s transformative, while others make the case that AI models will often output entire sections from articles included in the training data. It doesn’t help the matter that if you remove all art from a particular artist, like Piccaso, the AI won’t be able to output art “in the style of” that particular artist when prompted. Cases like the ongoing one by New York Times against ChatGPT will cause courts to have to evaluate this question.
If the law settles that including copyrighted material in a dataset that an AI is trained on is infringement, then Valve doesn’t want to be in a position where they have a large number of games that are infringing that they willingly allowed on their platform. By requiring these disclosures, Valve now can not only easily track which games need to have actions taken against them, but also can make a stronger case that the developers are the ones who should be held responsible for the infringement rather than Valve since they submitted affirmations that they weren’t infringing. In this way, the policy still is focused on avoiding copyright infringement, not taking a stand against any specific emerging technology.
It’s worth noting that in such a scenario, large companies that have access to a large amount of art assets that they hold the copyright over will be able to produce their own datasets without infringement. This will remain out of reach for smaller and indie developers, essentially making AI-generated art an impossibility for them.
Valve’s new policy clarification also states that they will “evaluate the output of AI generated content in your game the same way [they] evaluate all non-AI content – including a check that your game meets those promises.” In other words, this review process will be the same as checking for other copyright infringement.
Conclusion
Valve’s new policy continues to not actually change much, but it does offer more clarity. AI isn’t banned on Steam. Copyright infringement isn’t allowed. Whether or not the inclusion of copyright-protected assets in a dataset is infringement isn’t a question that Valve can settle, but is a question for the courts.
Valve is just taking a proactive approach so that they can be ready if the courts do decide one way or the other on that question.
Have more questions about your own situation? Schedule a free consultation and we’ll talk.
- Naruto v. Slater, No. 16-15469 (9th Cir. 2018) ↩︎